
2025年のCEDECで発表した内容のうち、今回はメッシュレット圧縮のサンプルプログラムを公開しようかなと思います。
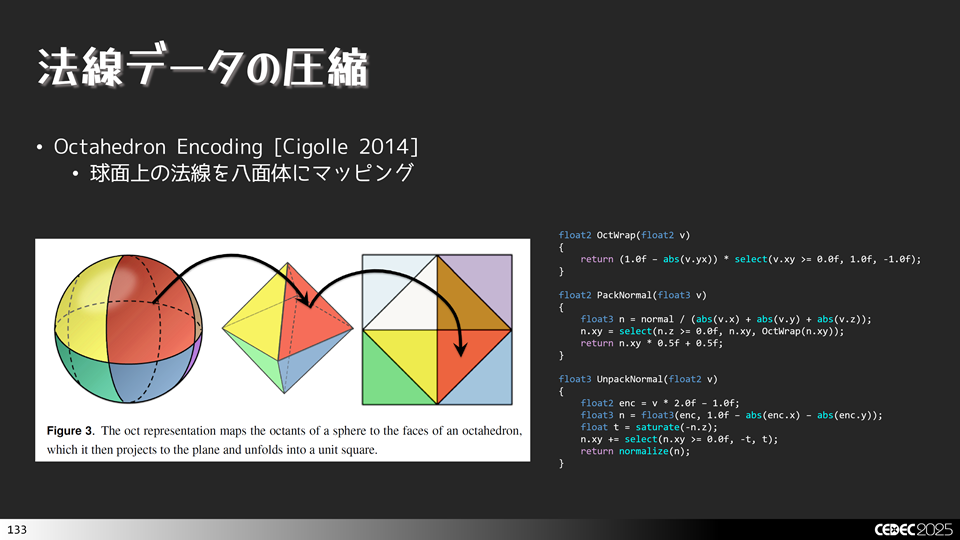
いわゆる八面体エンコーディングというやつです。
下図のように,八面体にマッピングして,それを静方向に収まるように変換します。こうすることで,3次元座標を2次元座標に次元を落とすことができるので,データ削減が行えます。G-Bufferにデータを格納する際に利用したり,メッシュデータのサイズを減らす際に利用したりします。
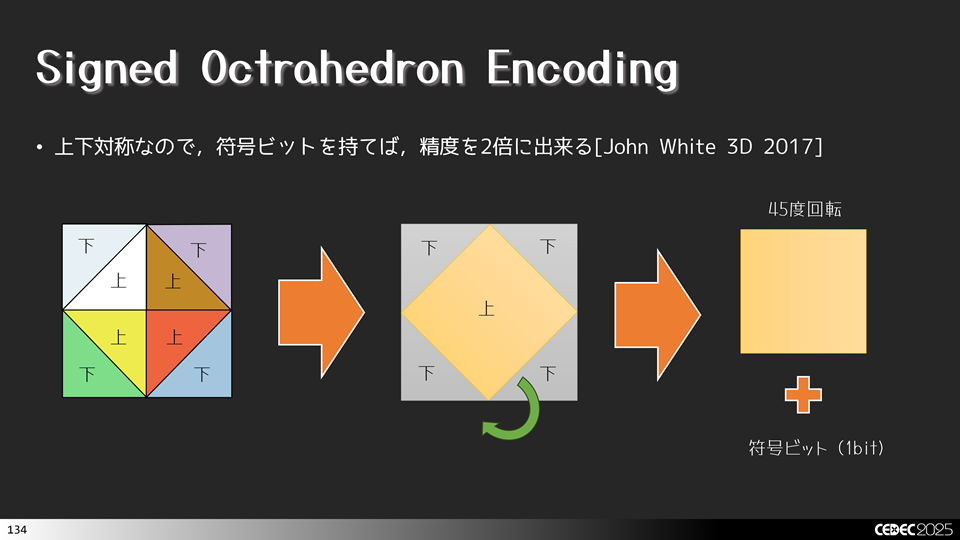
球のデータというのは上下対象なので,上半分だけデータを持って,下側は符号ビット持って表現すれば,下側のデータを削減することができるじゃない!と考えた人がいました。符号ビットを持つことで,次元は落とせないですが空いた領域を精度向上に利用することができます。これをSigend Octahedron Encodingといいます。
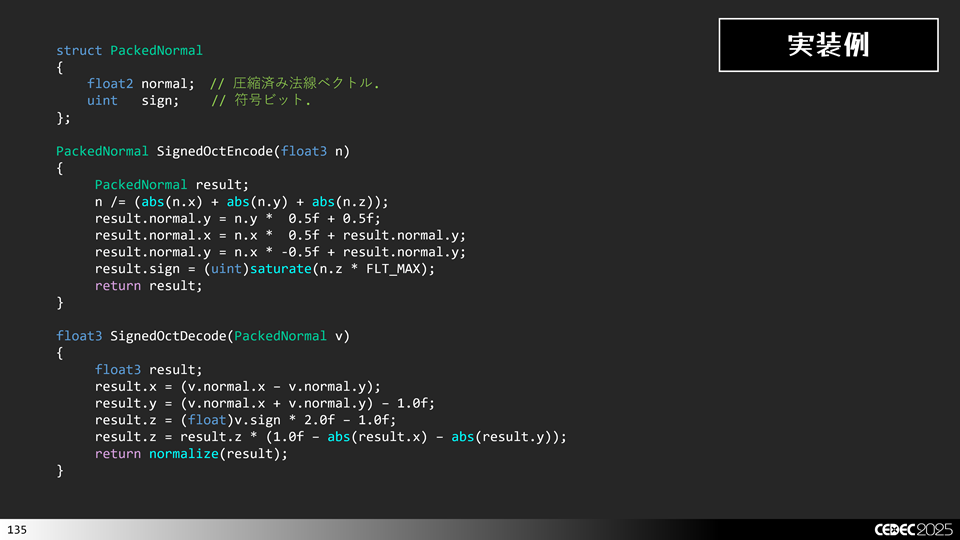
実装例は下記のようになります。
法線データをOctahedron Encondingで圧縮できました。どうせなら,接線ベクトルや従接線ベクトルも圧縮したいところです。そうすればG-Bufferのデータ量やメッシュデータのサイズを減らすことができます。従接線ベクトルは外積で計算すれば復元できるので,接線データをどうやって圧縮するというのがポイントになってきます。SIGGRAPH 2020で,接線ベクトルを角度として,表し次元数を減らすという手法が紹介されています[Geffory 2020]。この手法の詳細は下図になります。
![[Geffroy 2020]の接線空間圧縮](images/d3d12_028/meshlet_compression_05.png)
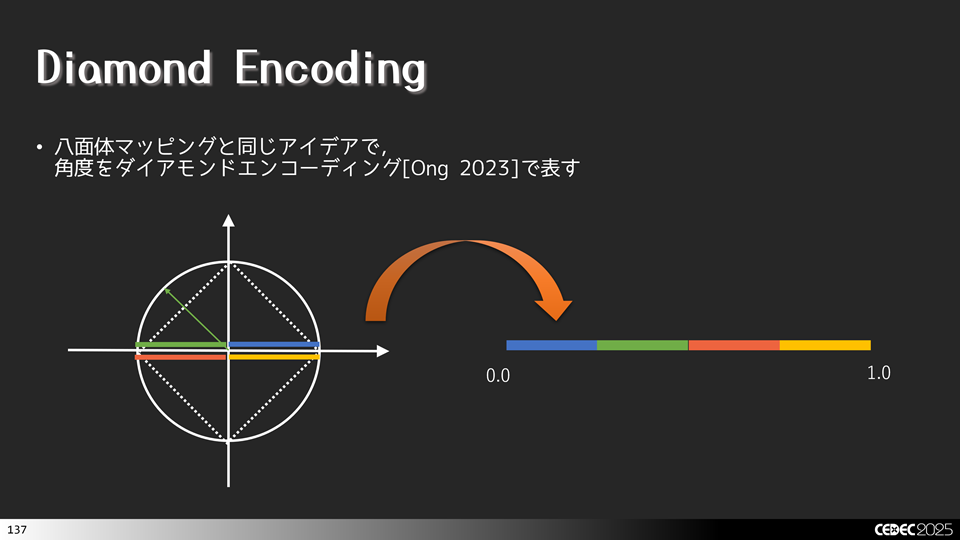
上図を見るとわかるのですが,角度として表す関係で,角度()を求めるのが面倒なのと,復元する際に,sinやcosといった超越関数が入ります。このあたりの処理は意外と重いので,できることなら簡単な命令に置き換えたいところです。そこで考えた頭のいい人がいました,「八面体マッピング」と同じ感じで2Dで表せばよいじゃないかと。八面体マッピングと同じアイデアで,角度をDiamond Encoding[Ong 2023]で表します。
実装は下記のようになります。
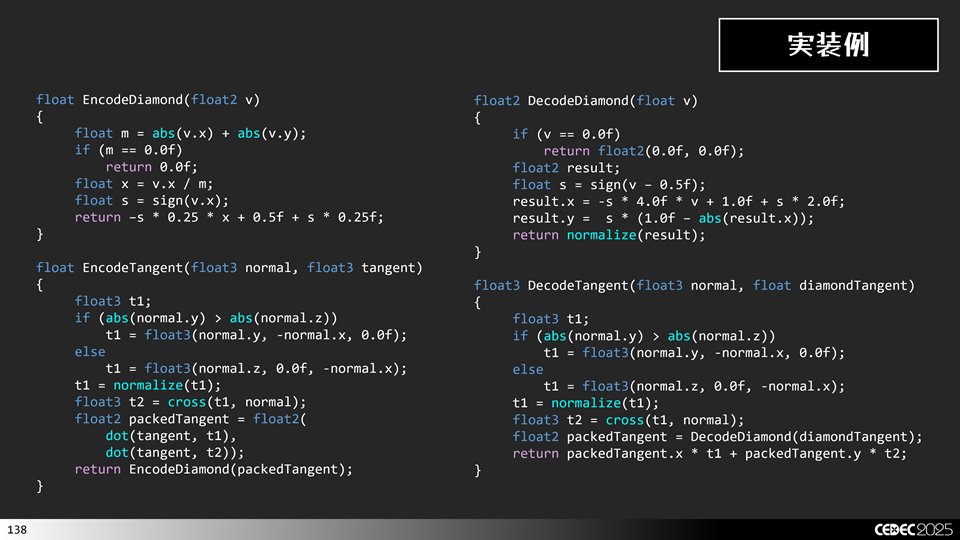
今、接線を表すのに使いたいので,基本的にはゼロベクトルになることはないと考えます。そこで,ゼロベクトルを表さなくてよくなるので,ゼロベクトルを表現するための分岐処理を上記から外すことができます。ゼロベクトルを表現できなくする代わりに,実装を簡略すると次のようになります。
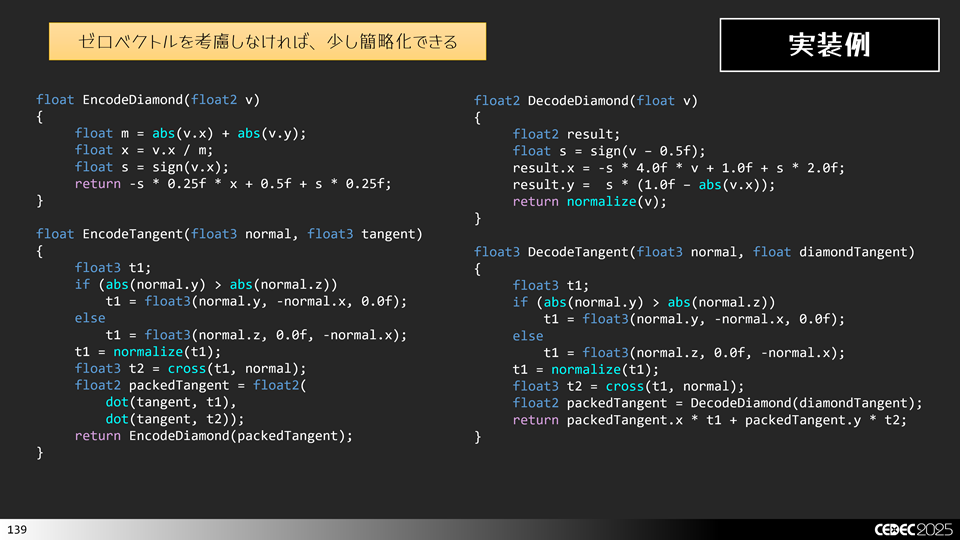
当然ながら、先ほど八面体エンコーディングで紹介した符号ビットで表す手法はダイアモンドエンコーディングにも適用可能です。

先程と同様にゼロベクトルを表現しなくてもよいのであれば、下記のように簡略化できます。

ちょっと精度は落ちますが,そもそも接線データを持たずに,計算で復元する手法というのが ShaderX5に紹介されています[Schüler2007]。ddx, ddyを用いて接線と従接線データを復元します。下図のような感じです。
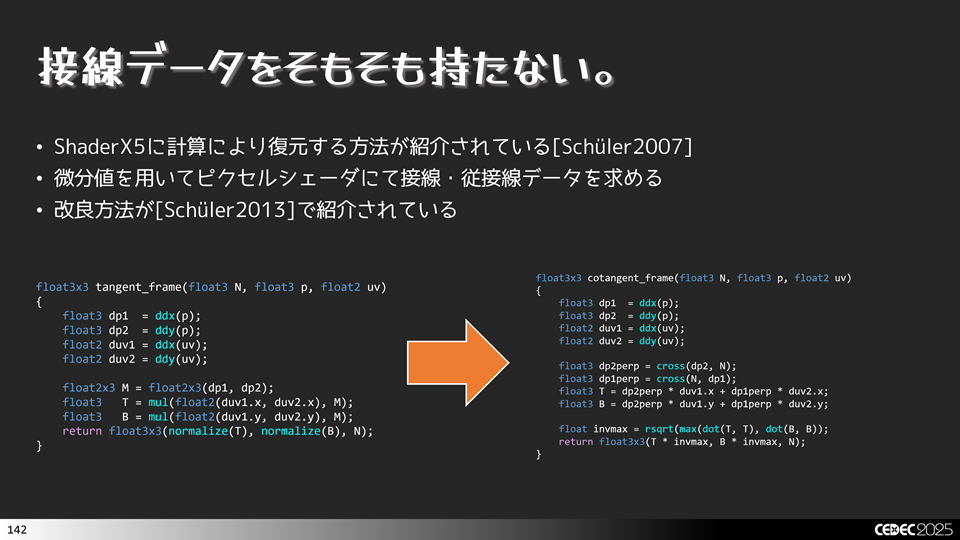
詳細な説明については下記の著者のブログで紹介されているので,気になる方は参照してみてください。
法線や接線は八面体エンコーディングやダイアモンドエンコーディングで表現できますが,こうした手法が使えないデータもあります。例えば,位置座標やテクスチャ座標などです。こうした場合はどうすればよいでしょうか?そこで出てくるのが,量子化によるデータサイズ削減です。UE5などでも使われている手法です。
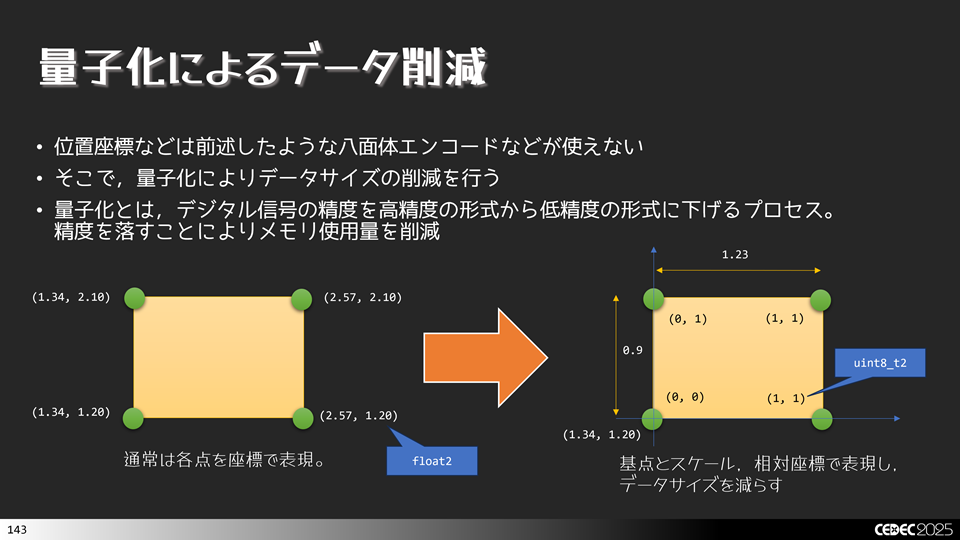
例えば,左側のように真面目に表現しようとすると,float2 X 4 のデータが必要になります。つまり,64 * 4 = 256 bit が必要です。これに対して量子化は基点とスケール,相対座標で表現してデータサイズを減らします。右側のように, float2 + uint8_t2 * 4 + float * 2 のデータで表現します。つまり,64 + 16 * 4 + 4 * 2 = 136 bit になります。約 0.53倍程度に減らすことができています。
量子化する際の注意点としては,スケールの求め方です。個別にスケールを求めてしまうと,下記のようにクラックと呼ばれる穴あきが発生してします。クラックを回避するためには,スケールを個別の尺度でもとめるのではなく,全体で統一した尺度で求めてあげればよいです。

あとは、実装ですね。下記のような感じで実装してあげればよいです。
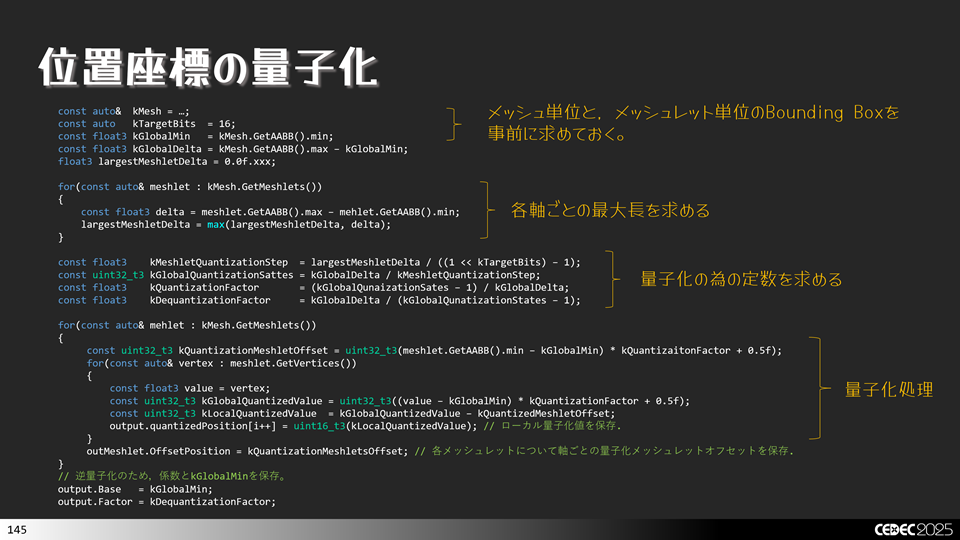
これで,データ圧縮できました。圧縮データをアセットとして保存してあげたり,GPUに送る際に利用するなどしてあげればよいです。使う際に,逆変換をかけてデータを復元してから利用します。これには,基点とスケールのデータを使って計算を行います。下図のような感じです。
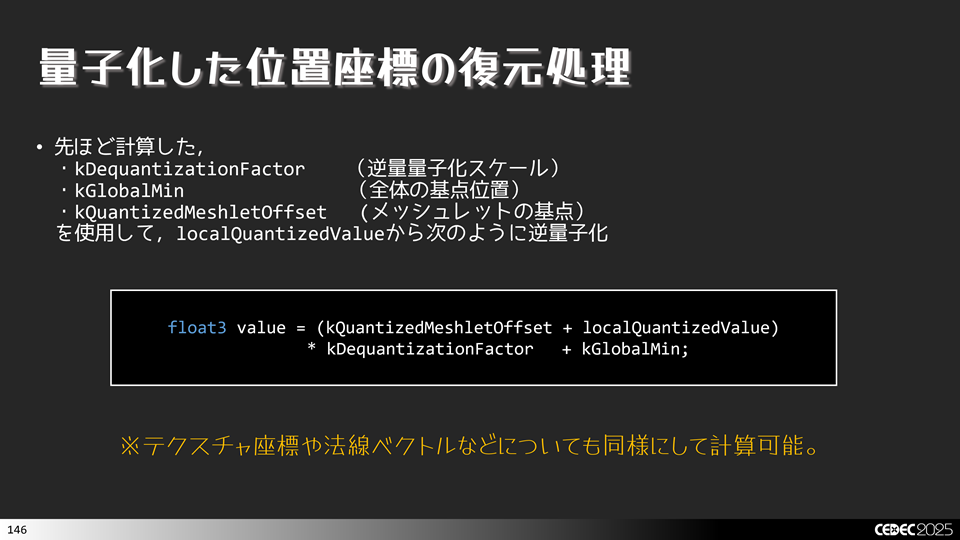
上記の処理をシェーダ上で計算してあげればよいでしょう。
メッシュシェーダを利用する場合,最大256頂点までしか出力できないので,頂点インデックスを表現するには 8 bit あれば十分です。従来 32 bit を使っていた場合は,1/4程度にデータを削減できます。16 bit インデックスを利用している場合でも,1/2程度削減できます。 …というわけで 8 bit を利用します。ただ、使う際に注意点があって,ByteAddressBufferは通常4byteアライメントなので,アライメント境界をまたぐ場合に注意が必要です。HLSL 2021になって最近ようやくビットフィールドが使えるようになったので,こうした面倒ごとを回避できるようになりましたが,HLSL 2021にまだ移行していないプロジェクトなどでは,悩みの種になります。こうしたビットフィールドが使えず,4byte単位でのアクセスを強いられるケースでは,下記のように実装することで,対応することができます。

製品ビルドなどでは,下記のようにgroupsharedメモリなど高速なメモリにいったん格納してからアクセスしてしまった方が良いかと思います。

今回は,CEDEC 2025で発表した内容のうち,データサイズ削減についての話でした。実際に実装コードは下記のサンプルコードを参照してください。
本ソースコードおよびプログラムはMIT Licenseに準じます。プログラムの作成にはMicrosoft Visual Studio Community 2026を用いています。